Chapter 14: The Digital Situation


This chapter completes the unit on rhetoric's "situations" by discussing the digital situation of rhetorical communication. It is divided into three sections: The first discusses what the Digital Situation is. The second defines two keywords, "algorithm" and "big data." The final section, on digital dystopia and algorithms of oppression, describes how rhetoric helps us to understand the problems generated by profit-focused digital technologies/platforms. There are two videos that accompany the third section that I also strongly recommend.
To allay any confusion, there is no chapter 13 in the un-textbook. Much like the floors of some buildings, the chapters skip from chapter 12 (on "the secrecy situation") to chapter 14 (on "the digital situation"). My (admittedly superstitious) reasoning for this otherwise puzzling decision is that I would just prefer not to end this textbook on a '13'.
Watching the video clips embedded in the chapters may add to the projected "read time" listed in the headers. Please also note that the audio recording for this chapter covers the same tested content as is presented in the chapter below. This chapter has been edited from the original transcript to improve the readability and the clarity of the covered concepts. If you are seeking the original transcript used to compose the recordings below, please follow this link.
Chapter Recordings
- Part 1: What is Digital Rhetoric? (Audio, ~20m, recording by Milena Yishak)
- Part 2: Keywords for the Digital Situation (Audio, ~20m, recording by Makayla Hillukka)
- Part 3: UnTextbook Recording (Audio, ~13m, recording by Makayla Hillukka), Digital Dystopia and the Algorithms of Oppression (Both Videos, ~35m)
Read this Next (for COMM 3601 @ UMN-TC)
Part 1: Defining Digital Rhetoric
Digital Rhetoric describes the language we use and the practices that have become invisible/normal concerning technology. The basic premise is that the words and techniques we use to monitor and model human behavior have consequences. This chapter answers the questions: which words, phrases, and language choices define the "digital situation" of rhetoric? What techniques or strategies are part of the digital situation? What are its practical and lived effects?
Beyond offering this core definition and answering the questions above, this chapter explains how digital rhetoric also describes the way that words about technology and techniques of measurement are used to model human behavior, the way that digital technologies retain the trace of earlier communication technologies, and the destructive effects of the terminology used to categorize technology and digitally-enabled measurement techniques.
What is the "Digital Situation"?
The "digital situation" describes the effort to situate the theories and methods of rhetoric to the new environment of digital communication. According to rhetorical scholars Damien Smith Pfister and Michelle Kennerly,
The invention of writing, like the invention of print and digital media after it, did not signal the end of oral communication, though it did transform oral norms and many of the practices that accompanied oral culture. However, even in digital contexts, oral communication merits continued attention because, as the scholar of media and rhetoric Marshall McLuhan famously claimed, “the ‘content’ of any medium is always another medium. The content of writing is speech, just as the written word is the content of print, and print is the content of the telegraph.
The digital era also corresponds with the invention of computational technologies, operating systems, and internet-enabled connectivity is often described as a wholly new historical situation, one that marks an important departure from previous technological ages. The beginning of this "situation" is often located somewhere between the 19th-century invention of difference and analytical engines and the 20th-century development of computerized cryptography, and features western European inventors such as Ada Lovelace, Charles Babbage, and Alan Turing. However, many early computational technologies retain the trace of older technologies. Some, like the analytical engine, were powered by steam, while others, like the Turing machine, are no more complicated than a basic calculator. Additionally, the word "computer" originally described a class of professional mathematicians, like Dorothy Vaughan, whose work was crucial for space travel in the 20th-century. Practitioners like Vaughan, who were subjected to vicious discrimination and have been long overlooked in the history of the digital age, offer a window into how allegedly "new" forms of media retain older forms of technology and the cultural assumptions that surrounded them.
In the case of the digital era, many 'new' technologies have strong resemblances to their older antecedents and the discriminatory patterns of thought that characterized them have not disappeared but instead, have changed forms. For example, in Plato's Phaedrus, which is one of the few ancient Greek works in the philosophical tradition that references the term rhetoric, he describes an ancient skepticism to a different form of technology: writing. In that dialogue, the character-teacher Socrates argues that speech is superior to writing because it captures the living intentions of the speaker and the liveliness of the spoken encounter. Writing confines the communication of knowledge to the dead letter, where it is mummified and separated from its original source. When such sources are absent, they cannot resolve the conflicts over interpretation, misuse, or misunderstanding. Writing, he also argues, is a crutch for memory, and weakens the mind by diminishing our capacity for retaining information. In many ways, this criticism of writing resembles criticisms of those brought up in the early digital era. As one pundit argued of Gen Z in 2019:
They are bright, innovative, confident in their skills on all manner of digital screens and devices: This is Generation Z, many of whom have little notion that they have begun to short-circuit some of the essential cognitive and affective processes that produced the digital world they inhabit. Furthermore, no small number of these young humans would grimace if asked to read this last sentence with its multiple clauses and syntactical demands. Reports from university and high school instructors like Mark Edmundson describe how many students no longer have the patience to read denser, more difficult texts like classic literature from the 19th and 20th centuries. I am less concerned with students' cognitive impatience than with their potential inability to read with the sophistication necessary to grasp the complexity of thought and argument found in denser, longer, more demanding texts, whether in literature and science classes or, later, in wills, contracts, and public referenda. The reality is that our young people are changing in ways that are as imperceptible to them as to most adults, particularly in how, what, and why they read—the cornerstone of how most humans think for the last few centuries with the spread of literacy.
In the digital era, the more things change, the more they stay the same. According to the author quoted above, people residing in wealthy, technology-consuming nations are on the precipice of a landmark generational change, with less memory of a pre-digital environment and more default, early-age engagements with digital technologies. The author's fears about Gen Z's reading habits resemble Socrates' fears about "memory" in the sense that both technological shifts are suspected to alter the course of human development. However, what neither author captures is how technologies like writing were – and computers are – unequally distributed among a social hierarchy of different peoples. While it may be true that Gen Z's reading habits may be changing, that may not be fully representative of the digital situation, such as for people who reside in exploited technology-manufacturing countries, for those who cannot afford such technologies, for those ignored by the design process, and for those targeted by surveillance. In the digital situation, many new media technologies retain traces of the social world of which they were a part, including the discriminatory policing, sexism, and racism that also characterized earlier eras of technological innovation and change.
Effects of the Digital Situation
So, what difference does the "digital" make? What's "new" about new media? What are the consequences of the digital situation for rhetoric and rhetorical forms of communication?
(1) The first consequence of the digital situation is that rhetoric about digital technologies is saturated with profound optimism and anxiety.
Because the digital age also increases the quantity of information with which we are routinely engaged, anxiety is rhetorically rendered as short-lived neologisms like information overload, the short-lived too-much-information effect, information anxiety, and infobesity (Bawden and Robinson, "The Dark Side of Information," 181-5). As media theorist Mark Andrejevic claims, “we have become like the intelligence analysts overwhelmed by a tsunami of information or the market researcher trying to make sense of the exploding data ‘troves’ they have created and captured.”
One reason that this information creates such anxiety is that it implicates enormous populations with the release of sensitive information. Those who have had their information compromised share an experience of anxiety at a mass level. 164m LinkedIn passwords in 2012, 427m MySpace passwords in 2013, 1b Yahoo accounts in 2013, 40m credit card imprints from Target in 2013, and 25gb of user information from Ashley Madison in 2015. This continual, successive leaking moves at multiple more-or-less perceptible speeds.
The metaphor of information "leaks" is deeply rooted in the metaphor of information-as-fluid. The rapid growth and proliferation of digital technologies leads Gregory Seigworth and Matthew Tiessen to describe them as pools for data aggregation and plasma: more-than-liquid currency flowing in rapid transnational currents. James Gleick calls the information revolution of the 20th century a “flood” to compare the cascade of “dictionaries, encyclopedias, almanacs, compendiums of words, classifiers of facts, [and] trees of knowledge” to the rising tide of digital technology running from Charles Babbage to Sergei Brin. Klaus Theweleit writes that “the powerful metaphor of the flood engenders a clearly ambivalent state of excitement. It is threatening but also attractive … [and] causes many things to flow: every brook and stream, still waters; floods of papers, political, literary, intellectual currents, influences. Everything is in flow, swimming upon this wave or that, with or against the current, in the mainstream or in tributaries.”
(2) The second consequence of new digital technologies is that humans are imagined to be automatic choice-making communication machines, much like computers and other digital technologies.
This is most apparent in the recognition accorded to the work of behavioral economists Daniel Kahneman and Amos Tversky and their probabilistic theory of "heuristics" – mathematical rules of irrational human behavior – explained in the book Thinking Fast and Slow. A heuristic is a mental shortcut for reasoning that, when misapplied, may consistently predict erroneous human behavior, when given the proper set-up and context. An example of a heuristic is the "hot hand fallacy," in which multiple consecutive successful outcomes – such as basketball free throws or gambling bets – seem to increase the probability of subsequent successful outcomes. Whether the "hot hand" is in fact a fallacy is a matter of popular dispute.
According to (other) behavioral economists Richard H. Thaler and Cass R. Sunstein, authors of Nudge: Improving Decisions about Health, Wealth, and Happiness:
Unfortunately, people do not have accurate perceptions of what random sequences look like.” … “Players who have hit a few shots in a row or even most of their recent shots are said to have a “hot hand,” which is taken by all sports announcers to be a good signal about the future. … It turns out that the “hot hand” is just a myth. Players who have made their last few shots are no more likely to make their next shot (actually a bit less likely). Really. (27-8)
Other common examples of "heuristics" include anchoring and availability. The anchoring heuristic describes the approximations we make when we guess quantities or relative sizes. A person will typically begin with an "anchor" – a point of reference with which they are familiar – and guess from there. For example, when guessing the population of Madison, Wisconsin (~254,000) a correct guess may depend upon where you currently live. A resident of Chicago who knows the Illinois city has a population of 2.7 million but that Madison is significantly smaller might divide this number by 3, leading to a guess of 900,000. But someone who lives in Minneapolis, population 430,000 might, following the same logic, guess in the neighborhood of 143,000. Although the Minneapolis guess is still wrong, it is still significantly closer to the correct amount.
The availability heuristic describes a guess in which our ability to think of a relevant or vivid example may lead us to overestimate the risk of one event over another. If you are able to think of an example of something going awry, you may be more likely to be frightened, invested, and/or concerned than if such examples are not so readily available. For example, easily imagined causes of death such as tornadoes might be thought to cause greater devastation than other threats, such as asthma attacks. Similarly, recent events have a greater impact on our risk-based behaviors than those that occurred earlier in remembered time or recorded history.

One significant flaw in the humans-as-computing-machines metaphor is that it encourages ways of thinking that are mathematically precise but divorced from a larger social context where the effects of design vary greatly depending upon race, ability, gender, and class. In “A Culture of Disengagement in Engineering Education,” Erin A. Cech argues that engineering education, in particular, embraces the mentality that the world presents problems that can be solved by making the correct design choices, using decontextualized reasoning in which a solution employed under one specific set of circumstances will necessarily work in another, analogous context. The effect of this kind of abstraction is to ignore peoples' unique experiences of digital technologies and to generalize the communities where technological interventions are leveraged as 'solutions'. As Cech argues:
“Disengagement may mean that things like public welfare considerations get defined out of engineering problems, excluded from the realm of responsibility that engineers carve out for themselves.” … “Disengagement entails bracketing a variety of concerns not considered directly ‘relevant’ to the design or implementation of technological objects and systems, such as socioeconomic inequality, history, and global politics.”
One example of this kind of disengagement is the proposal for "Amazon Go," a fully automated retail location run by the larger Amazon.com parent company. In 2016, Amazon.com introduced the idea of a worker-less store where Amazon customers would use a digital scanning system to gain access to a store and to pay for items. As advertised, this concept offered a seamless customer experience in which they could quickly walk in and out with what they needed. The advertisement features a diverse array of customers, seemingly promising access to anyone who might wish to shop there. However, critics of Amazon Go quickly pointed out a number of flaws in the idea. The store, for instance, employs an intense form of customer surveillance to police shoplifting and the automation of the retail space effectively eliminated a number of jobs. Even before the creation of this warehouse/store, Amazon was credibly accused of having exacerbated housing insecurity. Having and gaining access to such a store would create even more visible divisions between those with food and housing, adding layers of difficulty for those without consistent housing – who would be prohibited from entering the store during inclement weather -- and for those who wished to use electronic benefits transfers (EBT) and other food vouchers. By eliminating jobs and promising access only to those who could afford a membership, such locations would contribute to worsening problems of gentrification by eliminating lower-paying jobs and by making housing insecurity more visible – all the while promising easier, faster access to food and other basic needs.
(3) The third consequence of the digital situation is related to the idea that every new technology bears the trace or residue of an older one.
According to Jay David Bolter and Richard Grusin, "the content of new media is old media." This phrase refers to the way that technology evolves, and how each "new" technological form retains the residue of the technologies that came before it. Remediation: Understanding New Media (2000), Bolter and Grusin argue media forms undergo a living evolution. Each new media form relies upon its predecessors for its meaning and its shape. PowerPoint, for instance, retains the "slides" from the images carousel and transparencies used on overhead projectors. The first computer programs were "written" upon punched paper cards, which were modeled after the Jacquard loom, which used interchangeable, patterned plates to create complex fabric designs.
The trace of old technology in the new is called a skeuomorph. The punched card, for instance, retained a similar form and function to the 'cards' of the Jacquard loom. The floppy disk retained a similar function to the punched card, which was similarly inserted into computer equipment as it was read by a computer. The CD and the DVD retained a similar form and function to the floppy disc, which became the 'new' data storage devices read through optical technologies. Other common skeuomorphs include the standard "save" icon, which resembles a floppy disk, the "trash" or "recycle bin," which may not in fact remove data from the hard drive, or the common "folder" image, which in many cases looks like a folder that might be used in a filing cabinet. These images and representations are residues of earlier, related technologies of storage and transmission. They remind us of old physical storage media even as files are stored in virtual spaces, such as "clouds" and "servers."

As N. Katherine Hayles explains in the (1999) How we Became Posthuman:
A skeuomorph is a design feature that is no longer functional in itself but that refers back to a feature that was functional at an earlier time. The dashboard of my Toyota Camry, for example, is covered by vinyl molded to simulate stitching. The simulated stitching alludes back to a fabric that was in fact stitched, although the vinyl "stitching" is formed by an injection mold. Skeuomorphs visibly testify to the social or psychological necessity for innovation to be tempered by replication. Like anachronisms, their pejorative first cousins, skeuomorphs are not unusual. On the contrary, they are so deeply characteristic of the evolution of concepts and artifacts that it takes a great deal of conscious effort to avoid them.

Skeuomorphs are the bits of new technology that remind us of its older versions. They are not just accidental features, unnecessary designs, or weird nostalgia; they are also a necessary part of technological evolution whereby already-familiar aspects of technology inhabit and inform the creation of the new. Recalling these aspects of technology – their superfluous but also essential features – is an important part of how they communicate across time.
Part 2: Keywords for the Digital Situation
This section introduces two key terms for the digital situation: algorithm and big data. As discussed in the previous section, these terms carry the weight of the old even as they symbolize what is 'new' about the digital situation and the transformative technologies it delivers. An important feature of these terminologies is that the older meanings and functions attached to media technologies still inform how we understand new media technologies. Rhetoric informs this understanding of media because it is similarly an "older" vocabulary that informs how many "new" techniques of persuasion and social action take shape in the 21st century.
Algorithm
According to the Oxford English Dictionary, the term algorithm originates from Arabic as a poor translation of the name al-Khwarizmi, the Persian author of a groundbreaking mathematical text on Arabic numerals. As cultural studies Ted Striphas explains in his essay, "Algorithmic Culture":
[The] manuscript, Al-Kitāb al-Mukhtaṣar fī ḥisāb al-jabr wa-al-Muqābala (The Compendious Book of Calculation by Restoration and Balancing) is the primary work through which the word algebra itself, adapted from the Arabic al-jabr, diffused through Moorish Spain into the languages of Western Europe Incidentally, the word appearing just before al-jabr in the Arabic version of the title, ḥisāb, though translated as calculation, also denotes arithmetic.
There is a similiarly complex history and evolution to the development of the term "algorithm." It signifies the conceptual discovery of the zero and its incorporation into the number system. Even "zero" has a complex past because it has migrated across cultures and languages. Zero comes from sunya, the Sanskrit word for ‘void.’ This term migrated into the Arabic context as sifr, which means ‘empty’ and is the root from which the modern term cypher derives.
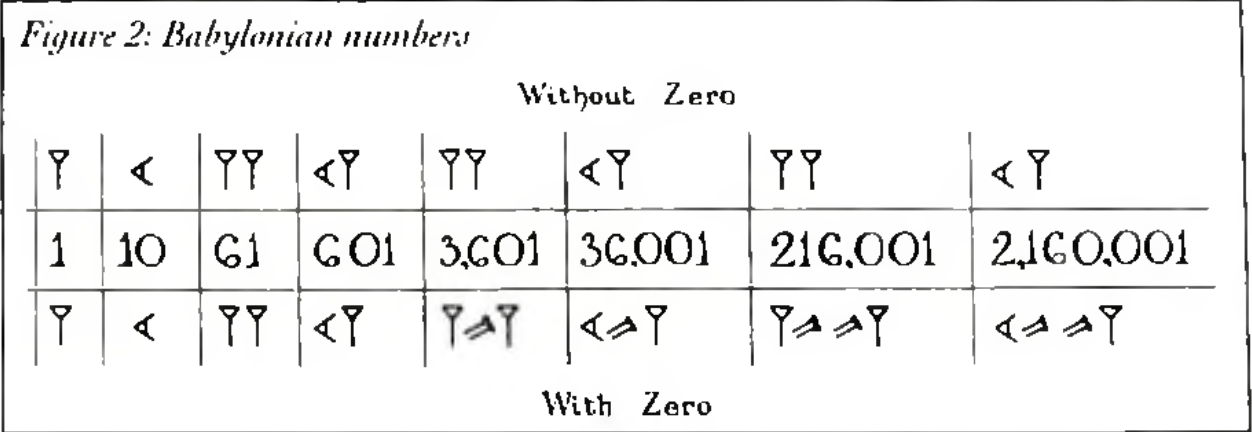
According to Charles Seife's Zero: The Biography of a Dangerous Idea, zero’s earliest known function is as a placeholder to symbolize a blank place in the abacus. It was used to distinguish between numbers like “61” and “3601,” which the Babylonian system of written notation would otherwise represent identically. Zero is an exceptional digit, appended to existing number systems to indicate separation or distance between known values. Much like their disdain for rhetoric, the ancient Greeks “so despised zero that they refused to admit it into their writings, even though they saw how useful it was.” (19) It poses an exception to the rule of number, both more and less than any other. It has extra characteristics relative to other numbers because it begins the number system, it is also less because, unlike other digits, it has no value and does nothing to increase or subtract from them.
The history and development of algorithms from a mathematical system of calculations into a proprietary technology is part of the reason why they seem to exercise a covert form of control over what we know and the decisions we make. As rhetoric and algorithm expert Jeremy David Johnson writes,
The alchemic mysticism of algorithms is due in large part to their opacity, hiding from view how they govern networked reality. Democratic governance in networked spaces seems increasingly out of reach, particularly as algorithmic systems become “black boxes” hidden from public view. In response to exploits and security concerns, and with the promise of more cash, many central tech developers have closed off the code to their systems. (Information Keywords 2021, 35)
Algorithms are mysterious for a number of different reasons. They originate with a system of arithmetic that seems divorced from a contemporary context in which mathematical protocols dictate how we search, find, and consume data. They have evolved into "black box" technologies, whereby the contents of a given algorithm is impossible to know because it a private and protected trade secret. Finally, they seem to wield secret control over our lives because they seem to exercise an invisible influence over us, steering our attention in ways that we do not percieve in the moment.
Contemporary scholars and scholarship define algorithms in the following way: as procedures and protocols written in programming langauges that curate our experience of digital content. Algorithms present this content in addictive and appealing ways while drawing their power from the aggregative power of data analysis. They dictate how we encounter information at a variety of levels. Algorithms shape how we present ourselves and circulate on social media platforms as well as the security of our purchases, platforms, and passwords. According to Chris Ingraham, "algorithmic rhetoric" describes three 'levels' of persuasion enabled by this digital infrastructure.
The macro-rhetorical level of algorithmic rhetoric "requires attention to the circulation of discourse that contributes to elevating the status of algorithms as valuable technologies. The stakes here are epistemological, having to do with what counts as valid knowledge claims.” (70) At this level, algorithms are conceptualized in general terms and celebrated for what they can (possibly) make known. It is a level of big claims, speculative investments, and dangerous idealism about the digital future. As Ingraham writes, “the macro-rhetorical invites us to think about how algorithms now “structure the planet” and come to “affect everything and everyone,” whether we know it or not.” (72)

The meso-rhetorical level of algorithmic rhetoric describes the choice-making that goes into the “The meso-rhetorical requires attention to identifying the category of technological operations we call “algorithms” as rhetorically constituted. The stakes here are ontological, having to do with the algorithm’s nature.” (70) Often, the meso-rhetorical level of algorithms is a "black box." As Frank Pasquale explains, the phrase "black box" often has a double meaning:
"[Black boxes] can refer to a recording device, like the data-monitoring systems in planes, trains, and cars. Or it can mean a system whose workings are mysterious; we can observe its inputs and outputs, but we cannot tell how one becomes the other. We face these two meanings daily: tracked ever more closely by firms and government, we have no clear idea of just how far much of this information can travel, how it is used, or its consequences. (The Black Box Society, p.3)
In other words, the meso-rhetorical level of algorithms describes the debates about what algorithms are, what is or is not included within their parameters, and how much of their protocols remain hidden or secret. The ability and correctness of employing algorithms to track and sell consumer data, for instance, would constitute a series of choices made by programmers in the interest of defining what an algorithm is.
The micro-rhetorical level of algorithmic rhetoric concerns their impacts and effects upon audiences. “The micro-rhetorical requires critiquing the repercussions and implications of algorithmic rhetoric in its particular instantiations.” (70) Such implications range from impacts upon communities to effects for a nation or population. In April 2009, Amazon.com garnered public attention for mis-categorizing a large library of literature. Cultural studies scholar Ted Striphas explains how the saga unfolded from the perspective of author Mark R. Probst in his essay, "Algorithmic Culture":
Hoping the matter was a simple mistake, he wrote to Amazon customer service. The agent who emailed Probst explained that Amazon had a policy of filtering ‘adult’ material out of most product listings. Incensed, Probst posted an account of the incident on his blog in the wee hours of Easter Sunday morning, pointing out inconsistencies in the retailer’s policy. The story was subsequently picked up by major news outlets, who traced incidences of gay and lesbian titles disappearing from Amazon’s main product list back to February 2009. In a press release issued on Monday afternoon, a spokesperson for Amazon attributed the fiasco to ‘an embarrassing and ham-fisted cataloging error’. More than 57,000 books had been affected in all, including not only those with gay and lesbian themes but also titles appearing under the headings ‘Health, Mind, Body, Reproductive and Sexual Medicine, and Erotica’. An Amazon technician working in France reportedly altered the value of a single database attribute – ‘adult’ – from false to true. The change then spread globally throughout the retailer’s network of online product catalogs, de-listing any books that had been tagged with the corresponding metadata (James, 2009b). This was not homophobia, Amazon insisted, but a slip-up resulting from human error amplified by the affordances of a technical system.
Big Data
The general term used to describe the transition to a mode of data analysis concerned with processing, analyzing, and monetizing large volumes of information is big data. The term captures a shift in how knowledge is defined and mobilized, one that is largely quantitative in nature and emphasizes the role of correlations – the probabilistic association of different data points or sets – over causation – the linear, one-after-another sequence of events in which the determinants of some phenomenon B are associated with some initating event A. According to Viktor Mayer-Schonberger and Kenneth Cukier, the authors of the 2014 book Big Data: A Revolution that Will Transform How We Live, Work, and Think,
"big data" refers to things one can do at a large scale that cannot be done at a smaller one, to extract new insights or create new forms of value, in ways that change markets, organizations, the relationship between citizens and government, and more. (6)
It is difficult to conceive of the size and scale of "big data," or the extent to which analyzable bodies of information have grown in the 20th and 21st centuries. The expansion of data concerns our ability to map the universe and the genome, as well as the storage and transmission of information via commonly used search engines like Google. It implicates events like cyberattacks, where the quantity and sensitivity of the information that is hacked or leaked consistently increases over time. It also concerns the kinds of networks that are formed and made possible through forms of digital connectivity, which are both employed in ways that promote community and that foster "networks of outrage" that unravel into baseless conspiracy theories and public violence. As rhetorical scholar Damien Pfister writes:
These phenomena are all enabled by the underlying abundance of information that encourages the creation of echo chambers or filter bubbles, which, in the wake of the events of 2016, have been understood as sites where “alternative facts” have ushered in “post- truth” politics. The anxieties around this outburst of proto- fascist emotion are warranted at the same time that they may be somewhat misplaced: truth has always been slipperier than philosophers and politicians have assumed, and today’s neo- fascist revival can be traced to liberalism’s latest crisis as a public philosophy and a widening rich/poor gap as much as information abundance. (Information Keywords 2021, 27)
The 'bigness' of big data is also connected to rhetoric in other ways, namely through the terms megethos and copia. These terms describe how speech may create the impression of tremendous size or volume.
The term megethos describes how rhetoric creates the impression of tremendous importance or magnitude. In his 1998 article, "Sizing Things Up," rhetorical scholar Thomas Farrell claims that "magnitude has to do with gravity, the enormity, the weightiness of what is enacted, a sense of significance that may be glimpsed and recognized by others." Megethos is what lends this gravitas to events, speech, and language. It is an aesthetic or presentational form that is traditionally focused on vision and what can (or cannot) be properly 'taken in' at a glance. One example of megethos is the framing and reporting of "mega-leaks," whereby huge troves of information are released into public. In the case of the Panama Papers released by the International Consortium of Investigative Journalists, megethos consisted in the sheer volume of the documentation. In 2016, Lisa Lynch and David Levine explained this "mega-leaking" in the following way:
The Panama papers consisted of “11.5 million files covering 40 years’ worth of transactions from over 14,000 law firms, banks and incorporation agencies that had hired the Panamanian law firm Mossack Fonseca to assist in creating offshore companies for purposes of tax avoidance. ... Though the documents were not released en masse, a total of 400 journalists from 76 countries pored through them using a purpose-built database and a customized social network that allowed them to communicate their findings securely. During the course of the investigation, which took over a year, all the journalists and their media outlets respected an embargo agreement that kept their findings secret until a pre-arranged collective deadline. (1)
As the authors also argue, the mega-leak is double-sided. On the one hand, it promotes a kind of openness and accountability that would have been impossible in earlier times, creating a site for transparency and public oversight. On the other hand, it also means that the "trove of information" that comes with mega-leaks has no pre-determined system or agency of analysis. Instead, "search and analysis functions fall to the public," making the significance of huge information archives difficult to assess and slow to reach a wider global public's attention.
Copia is a rhetorical term that describes the strategic creation of size through a pattern of repetition. It is a way of generating an impression of size or magnitude by enumerating all of a given object's features, so much so that it is apparent to the reader or audience that there is still more to tell about the topic that has not yet been enumerated. Copia describes endless, limitless plenitude, a kind of "whole" or "totality" that is alluded to but never perceived. When, for instance, the historian and philosopher Michel Foucault (1970) describes the creation of new knowledge in medieval Europe, he calls this information "plethoric and poverty-stricken." Although there was a lot of information, it was un-searchable and disorganized due to the protocols used to generate it. Sometimes, copia is described as a way to account for the rhetorical power of lists, which may make compelling arguments through a gratuitous enumeration of a given topic, performing magnitude through an excess of detail. A famous example is Francois Rabelais's 16th-century text, Gargantua and Pantagruel, which makes significant use of this trope.

As rhetorical scholar Thomas Conley (1985) explains in his article, "The Beauty of Lists: Copia and Argument,"
In a similar way, the “treatise” on the virtues of the herb “Pantagruelion” amplifies the stock epidectic topoi: first, a careful and detailed description of its appearance, its usefulness, ways of preparing it, and its inestimable virtues, both quotidian and those of the grander sort; then, famous incidents in history, both real and mythical, in which it played an important part; its role in the achievements of human ingenuity; its fortitude and strength; comparisons with other plants and with the gods and goddesses themselves, all documented with references to Pliny, Theophrastus, Galen, and various Arabian writers. “Pantagruelion,” of course, is hemp. The praise of Pantagruelion, that is, is an extended encomium on "rope." (98)
Another famous example of copia comes from the famous courtroom scene of a 1944 noir film, Double Indemnity. During the scene, detective Keyes questions an expert witness, Mr. Norton, the owner of the Pacific All Risk Insurance Company. Keyes's line of questioning, copied below, seeks to undermine Mr. Norton's assumption that the claim is invalid due to the circumstances of a suspicious death:
You've never read an actuarial table in your life, have you? Why there are ten volumes on suicide alone. Suicide: by race, by color, by occupation, by sex, by season of the year, by time of day. Suicide, how committed: by poison, by firearms, by drowning, by leaps. Suicide by poison, subdivided by types of poison, such as corrosives, irritants , systemic gases, narcotics, alkaloids, proteins, and so forth. Suicide by leaps, subdivided by leaps from high places , under the wheels of trains, under the wheels of trucks, under the feet o f horses, under steamboats. But, Mr. Norton, of all the cases on record, there's not one single case of suicide by someone jumping off the back end of a moving train. (also cited in Joan Copjec, Read My Desire, p.164)
The questioning relies on the copia trope because it provides a list of information as a kind of rhetorical proof that Mr. Norton's suspicions are unfounded. By enumerating all of the different ways that the insurance company has quantified and categorized risk, Keyes arrives at the conclusion that Norton's proposed explanation of events is highly improbable. In keeping with the theme of "the more things change the more they stay the same," rhetorical vocabularies function today as in the past. Terms like megethos and copia help to distinguish between the kinds of magnitude and the 'bigness' of big data.
Part 3: Digital Dystopia and Algorithms of Oppression
The digital situation is particularly representative of the way that rhetorical modes of communication can uphold existing hierarchies of power while also claiming to be wholly new or different from what has come before. This is especially the case with racist computer engineering terms, the way that optical technologies are designed for white skin pigmentation (such as this widely reported racist soap dispenser), and the regressive gender dynamics of Artificial Intelligence and Virtual Assistants (AI/VA) commonly used in the home and workplace. Taken together, these aspects of the digital situation illustrate how the unbridled optimism for what technologies can or might do to create a better world is a flawed perspective. Key critics of digital technology insist that manufacturers and consumers take into account the structural inequalities that inhabit new and digitally organized systems of communication.
Problems with Racist Computational Metaphors
One significant problem with the terminology used to designate computer hardware and software is that it carries the residue (or skeuomorph) of racist distinctions used to segregate and distinguish between differently raced populations. A key problem is that this terminology is often presumed to be neutral and objective, in the sense that these names denote components and processes and are not intentionally discriminatory. However, this language still carries a destructive and dehumanizing force even if those who employ the terminology have forgotten or choose to ignore their original significations.
In June [2020], against the backdrop of the Black Lives Matter protests, engineers at social media platforms, coding groups, and international standards bodies re-examined their code and asked themselves: Was it racist? Some of their databases were called “masters” and were surrounded by “slaves,” which received information from the masters and answered queries on their behalf, preventing them from being overwhelmed. Others used “whitelists” and “blacklists” to filter content.
Ultimately, a core issue is that existing terminologies flippantly reference historical dynamics of oppression as metaphors for the ways that storage and retrieval devices are organized, or otherwise, repeat a longstanding bias that associates "whiteness" with virtuous activity while consigning "Blackness" to the opposite. This kind of terminology supports unconscious biases and registers as a kind of linguistic violence because it implies that such distinctions are not serious or should be ignored when they are, in fact, deeply impactful.
A related criticism of these kinds of terminologies is that the effort to rename is good, but does not go far enough. Whereas corporations like Google and Intel have committed to more inclusive language and naming practices, this linguistic 'fix' does not necessarily address the deeper structural issues of representation and discrimination that are a part of Silicon Valley's corporate culture. One example is Timnit Gebru's expulsion from Google following her letter concerning the racial biases of the optical face-recognition artificial intelligence being developed at the company. According to Gebru, the company's reluctance to acknowledge the racist problems with its technology went beyond language choices or even facial recognition alone. The letter signaled that the larger environment of Silicon Valley characteristically espoused anti-racist values while producing technologies that reinforced existing racial biases. According to the MIT Technology Review:
On December 2, 2020, Timnit Gebru, the co-lead of Google’s ethical AI team, announced via Twitter that the company had forced her out.
Gebru, a widely respected leader in AI ethics research, is known for coauthoring a groundbreaking paper that showed facial recognition to be less accurate at identifying women and people of color, which means its use can end up discriminating against them. She also cofounded the Black in AI affinity group, and champions diversity in the tech industry. The team she helped build at Google is one of the most diverse in AI and includes many leading experts in their own right. Peers in the field envied it for producing critical work that often challenged mainstream AI practices.
Online, many other leaders in the field of AI ethics are arguing that the company pushed her out because of the inconvenient truths that she was uncovering about a core line of its research—and perhaps its bottom line. More than 1,400 Google staff members and 1,900 other supporters have also signed a letter of protest.
In other words, the metaphors used to describe computational technologies (e.g. "white-hats" and "black-hats") are a symptom of a deeper, structural problem in which the terminology and the function of digital technologies work to uphold conditions of structural inequality. Changing the language is a crucial step to changing these beliefs, but it is not sufficient to see just how deeply rooted and widespread racism is within contexts of digital design.
Problems with Programmed Gender Dynamics
Gender is represented by digital technologies such as the "virtual assistant," which reproduces relational expectations where women are assigned submissive or subordinate social roles. In "Asking more of Siri and Alexa," digital rhetoric scholar Heather Woods explains how Apple, Amazon, and other corporations reinforce regressive expectations about femininity and servitude by using voices and encouraging communicative patterns where technologies – many of which have a distinctly feminine voice as a default setting. Artificial Intelligence/Virtual Assistant technologies do the work of "digital domesticity," which "mobilizes traditional, conservative values of homemaking, care-taking, and administrative "pink-collar" labor. By making artificial intelligence-based products in the image of such traditionalist roles, the digital situation reproduces "stereotypical feminine roles in the service of augmenting surveillance capitalism." Virtual assistants are sold as a matter of consumer choice, being sold on the belief that the technology will enable them to do more things or free themselves from burden by spending money. However, these technologies often work the other way. By collecting user information for future monetization, virtual assistants also serve the financial goals of the company that manufactured it.
The unique rhetorical term that Woods lends to the feminine personification of AI/VA is persona. When rhetoric is understood as speech, persona refers to the constitution of an audience through the intentional choices of the speaker. Woods describes persona as a kind of mask, "a communicative strategy for imagining the self and the audience as connected in a particular, shared way."
The domestic sphere is one theater in which femininity has undergone technologically-mediated modifications whilst mobilizing traditional performances of persona. New arrangements of domesticity at once rely upon stereotypical identities of femininity while slightly altering them (White, 2015, p. 19). The concept of “digital domesticity” has been used by scholars to describe the re-articulation of “prototypical motherhood” (Chen, 2013, p. 511) in the blogosphere and, more generally, domesticity has served as a key organizing metaphor for the rise of “smart homes” (Spigel, 2001). Chen’s study of “mommy bloggers” demonstrates how possibly liberatory practices (namely: blogging about personal experiences of mothering) are disciplined by constraining language practices. This foreclosure of radical politics constitutes a reentry into what Chen calls “digital domesticity,” characterized by traditional norms of stereotypical femininity. As implied by the term, digital domesticity signifies the reworking of femininity through technological mediation.
The "particular, shared connection" invoked by AI/VA is one that should remind us of a long history in which feminine-presenting persons occupy a de facto subordinate role. Because the default settings of AI/VA are vocally feminized, programs like Siri and Alexa perpetuate this hegemonic and repressive way of thinking. However, AI/VA also cultivates unequal forms of gender relationality as a way to generate capital, enriching the technology companies who profit from the user's intimate relationship with the virtual product. If AI/VA is imagined as a proprietary profit-generating surveillance device, then it is one that is purchased by choice on the promises of relief and the technology's relationship to its users.
Problems with Unequal Digital Infrastructures
The third collection of problems with profit-forward digital platforms and technologies concerns the effects that they have at a wider population level. According to media scholar Zeynep Tufecki, the consumer-forward focus of digital technologies means that ethical considerations often fall to the side in favor of imagining new ways to get more clicks and likes. As a consequence of this kind of design, technology companies ignore the potentially addictive qualities of their digital environments, preying on people who are vulnerable to gambling or are unaware of how to keep their information secure. As Tufecki argues, digital platforms are "persuasion architectures," updated forms of familiar information systems like check-out counters and automated roadside speedometers. However, unlike these earlier forms of technology, newer digital platforms seek out exploitable psychological weaknesses on the part of consumers in the effort to turn a profit.
The problems with digital infrastructures also run significantly deeper, particularly when we consider the default assumptions that search engines encourage and reinforce. In Algorithms of Oppression, digital media scholar Safiya Umoja Noble describes the way that Google's allegedly neutral search platform reinscribes destructive gender roles through the "pornification" of women and girls – in other words – encouraging search results that reduce people to sexualized commodities. In the process, search engines also erase realistic and professional representations of women, Black people, and immigrant populations. Rather than prioritizing a social or public good, "Google biases search to its own economic interests – for its profitability and to bolster its market dominance at any expense" (27) As Noble explains:
Knowledge of the technical aspects of search and retrieval, in terms of critiquing the computer programming code that underlies the systems, is absolutely necessary to have a profound impact on these systems. Interventions such as Black Girls Code, an organization focused on teaching young, African American girls to program, is the kind of intervention we see building in response to the ways Black women have been locked out of Silicon Valley venture capital and broader participation. Simultaneously, it is important for the public, particularly people who are marginalized – such as women and girls and people of color – to be critical of the results that purport to represent them in the first ten to twenty results in a commercial search engine. They do not have the economic, political, and social capital to withstand the consequences of misrepresentation. If one holds a lot of power, one can withstand or buffer misrepresentation at a group level and often at the individual level. Marginalized and oppressed people are linked to the status of their group and are less likely to be afforded individual status and insulation from the experiences of the groups with which they are identified. The political nature of search demonstrates how algorithms are a fundamental invention of computer scientists who are human beings – and code is a langauge full of meaning and applied in varying ways to different types of information. Certainly, women and people of color could benefit tremendously from becoming programmers and building alternative search engines that are less disturbing and that reflect and prioritize a wider range of informational needs and perspectives (Algorithms of Oppression, 25-26).